Week 6 - Apache Spark APIs
 Edit on GitHub
Edit on GitHubThe Spark DataFrame and SQL API
A Gentle Introduction to Apache Spark on Databricks
Apache Spark on Databricks for Data Engineers
Fundamental concepts:
Spark is a distributed programming model in which the user specifies transformations. These transformations build up a directed acyclic graph (DAG) of transformations and action. An action begins the process of execution that graph of instructions, as a single job, by breaking it down into stages and tasks to execute across the cluster. The logical structures that we manipulate with transformations and actions are DataFrames and Datasets. To create a new DataFrame or Dataset, you call a transformation. To start computation or convert to native language types, you call an action.
Structured API Overview
Structured APIs are a tool for manipulating all sorts of data, from unstructured log files to semi-structured CSV files and highly structured Parquet (Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language) files. These APIs refer to three core types of distributed collection APIs:
- Datasets
- DataFrames
- SQL Tables and Views
Majority of the Structured APIs apply to both batch and streaming computation. This means that when you work with the Structured APIs, it should be simple to migrate from batch to streaming or vice versa with little to no effort. Structured APIs are the fundamental abstraction used to write the majority of data flows.
DataFrames and Datasets
DataFrames and Datasets are distributed table-like collection with well-defined rows and columns. Each column must have the same number of rows as all the other columns although you can use null to specify the absence of a value and each column has type information that must be consistent for every row in the collection. To Spark, DataFrames and Datasets represent immutable, lazily evaluated plans(transformations) that specify what operations to apply to data residing at a location to generate some output. When we perform an action on a DataFrame, we instruct Spark to perform the actual transformations and return the results. These represent plans of how to manipulate rows and columns to compute the user's desired result.
Schema: defines the column names and types of a DataFrame. You can define schemas manually or read a schema from a data source. Schemas consist of types meaning that you need a way of specifying what lies where.
Spark is effectively a programming language of its own. Spark uses an engine called Catalyst: Catalyst: maintains its own type information through the planning and processing of work. This opens up execution optimizations.
Structured APIs
| DataFrame | DataSet |
|---|---|
| untyped (Spark maintains them completely) | typed (checks whether types conform to the specification at compile time.) Only available to JVM based languages Scala and Java. |
DataFrames are Datasets of Type Row. The "Row" type is Spark's internal representation of its optimized in-memory format for computation. To Spark in Python and R there is no such thing as a Dataset, everything is a DataFrame and therefore we always operate on that optimized format.
Overview of Structured API Execution
- Write DataFrame/Dataset/SQL Code
- If valid code, Spark converts this to a Logical Plan
- Spark transforms this Logical Plan, checking for optimizations along the way
- Spark then executes this Physical Plan on the cluster
Logical Planning
The first phase takes user code and converts it into a logical plan (optimized version of the user's set of expressions) It does this by converting user code into an unresolved logical plan. The plan is unresolved because although your code might be valid, the tables and columns that it refers to might or might not exist. Spark uses the catalog, a repository of all table and DataFrame information to resolve columns and tables in the analyzer. The analyzer might reject the unresolved logical plan if the required column name does not exist in the catalog. If the analyzer can resolve it, the result is passed through the Catalyst Optimizer, a collection of rules that attempt to optimize the logical plan by pushing down predicates or selections. Packages can extend the Catalyst to include their own rules for domain-specific optimizations.
Physical Planning
After creating the optimized logical plan, Spark begins the physical planning process. The physical plan - often called Spark plan - specifies how the logical plan will execute on the cluster by generating different physical execution strategies and comparing them through a cost model. (Upon selecting a physical plan Spark runs all of this code over RDDs.)
Basic Structured Operations
DataFrame consists of a series of records that are of type Row and a number of columns that represent a computation expression that can perform on each individual record in the Dataset. Schemas define the name as well as the type of data in each column. Partitioning of the DataFrame defines the layout of the DataFrame or Dataset's physical distribution across the cluster. The partitioning scheme defines how that is allocated.
DataFrame
Create DataFrame:
df = spark.read.format("json/csv/..").load("Some/path")
Print Schema:
printSchemadf.printSchema()
Columns and Expressions
- Expressions - when you select, remove manipulate columns from DataFrames
Create Column:
from pyspark.sql.functions import col, columncol("someColumnName")column("someColumnName")
Explicit Column References
- If you need to refer to a specific DataFrame's column, you can use the col method on the specific DataFrame. This can be useful when performing a join and need to refer to a specific column in one DataFrame that might share the same name with another column in the joined DataFrame.
Expressions
- Columns are expressions. An expression is a set of transformations on one or more values in a record in a DataFrame. An expression created via the expr function is just a DataFrame column reference. expr("someCol") is equivalent to col("someCol")
Records and Rows
- Each row in a DataFrame is a single record as an object type Row.
- Spark manipulates Row objects using column expressions in order to produce usable values.
Create Rows:
from pyspark.sql import RowmyRow = Row("Hello", None, 1, False)
DataFrame Transformations
- We can add rows or columns
- We can remove rows and columns
- We can transform a row into a column or vice versa
- We can change the order of rows based on the values in columns
DataFrame API Example Using Different types of Functionality
Reading Data:
df = spark.read \.option("header", True) \.option("sep", ",") \.option("inferSchema", True) \.csv("PATH/file.csv")
show()
If you want to see top 20 rows of DataFrame in a tabular form then use the following command.
carDataFrame.show()

show(n)
If you want to see n rows of DataFrame in a tabular form then use the following command.
carDataFrame.show(2)

take()
take(n) Returns the first n rows in the DataFrame.
carDataFrame.take(2).foreach(println)

count()
Returns the number of rows.
carDataFrame.groupBy("speed").count().show()

head()
head () is used to returns first row.
resultHead = carDataFrame.head()println(resultHead.mkString(","))

head(n)
head(n) returns first n rows.
resultHeadNo = carDataFrame.head(3)println(resultHeadNo.mkString(","))

first()
Returns the first row.
resultFirst = carDataFrame.first()println("fist:" + resultFirst.mkString(","))

collect()
Returns an array that contains all of Rows in this DataFrame.
resultCollect = carDataFrame.collect()println(resultCollect.mkString(","))

Basic DataFrame functions:
printSchema()
If you want to see the Structure (Schema) of the DataFrame, then use the following command.
carDataFrame.printSchema()

toDF()
toDF() Returns a new DataFrame with columns renamed. It can be quite convenient in conversion from a RDD of tuples into a DataFrame with meaningful names.
car = sc.textFile("src/main/resources/fruits.txt").map(_.split(",")).map(f => Fruit(f(0).trim.toInt, f(1), f(2).trim.toInt)).toDF().show()
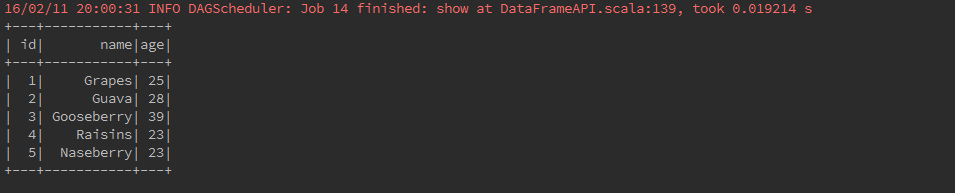
dtypes()
Returns all column names and their data types as an array.
carDataFrame.dtypes.foreach(println)

columns ()
Returns all column names as an array.
carDataFrame.columns.foreach(println)

cache()
cache() explicitly to store the data into memory. Or data stored in a distributed way in the memory by default.
resultCache = carDataFrame.filter(carDataFrame("speed") > 300)resultCache.cache().show()
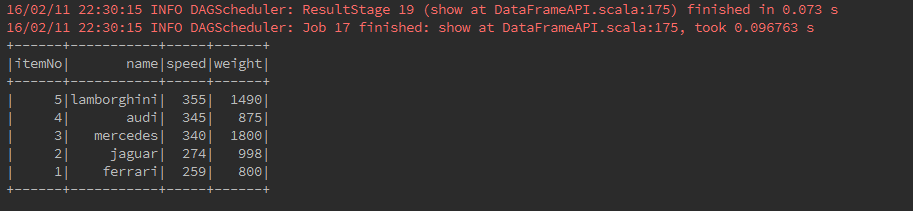
Data Frame operations:
sort()
Returns a new DataFrame sorted by the given expressions.
carDataFrame.sort($"itemNo".desc).show()

orderBy()
Returns a new DataFrame sorted by the specified column(s).
carDataFrame.orderBy(desc("speed")).show()

groupBy()
counting the number of cars who are of the same speed .
carDataFrame.groupBy("speed").count().show()

na()
Returns a DataFrameNaFunctions for working with missing data.
carDataFrame.na.drop().show()

as()
Returns a new DataFrame with an alias set.
carDataFrame.select(avg($"speed").as("avg_speed")).show()

alias()
Returns a new DataFrame with an alias set. Same as
as.
carDataFrame.select(avg($"weight").alias("avg_weight")).show()

select()
To fetch speed-column among all columns from the DataFrame.
carDataFrame.select("speed").show()

filter()
filter the cars whose speed is greater than 300 (speed > 300).
carDataFrame.filter(carDataFrame("speed") > 300).show()

where()
Filters age using the given SQL expression.
carDataFrame.where($"speed" > 300).show()

agg()
Aggregates on the entire DataFrame without groups.
carDataFrame.agg(max($"speed")).show()

limit()
Returns a new DataFrame by taking the first n rows.The difference between this function and head is that head returns an array while limit returns a new DataFrame.
carDataFrame1.limit(3).show()

unionAll()
Returns a new DataFrame containing union of rows in this frame and another frame.
carDataFrame.unionAll(empDataFrame2).show()

intersect()
Returns a new DataFrame containing rows only in both this frame and another frame.
carDataFrame1.intersect(carDataFrame).show()

except()
Returns a new DataFrame containing rows in this frame but not in another frame.
carDataFrame.except(carDataFrame1).show()

withColumnRenamed()
Returns a new DataFrame with a column renamed.
empDataFrame2.withColumnRenamed("id", "employeeId").show()

drop()
Returns a new DataFrame with a column dropped.
carDataFrame.drop("speed").show()

dropDuplicates()
Returns a new DataFrame that contains only the unique rows from this DataFrame. This is an alias for distinct.
carDataFrame.dropDuplicates().show()

describe()
describe returns a DataFrame containing information such as number of non-null entries (count),mean, standard deviation, and minimum and maximum value for each numerical column.
carDataFrame.describe("speed").show()

Show the Data
If you want to see the data in the DataFrame, then use the following command.
carDataFrame.show()

printSchema Method
If you want to see the Structure (Schema) of the DataFrame, then use the following command
carDataFrame.printSchema()

Select Method
Use the following command to fetch name-column among three columns from the DataFrame
carDataFrame.select("name").show()

Filter Method
Use the following command to filter whose speed is greater than 300 (speed > 300)from the DataFrame
carDataFrame.filter(carDataFrame("speed") > 300).show()

Working with Different Types of Data
Objectives
- Booleans
- Numbers
- Strings
- Dates and Timestamps
- Handling Null
- Complex Types
- User Defined Functions
Where to look for APIs? DataFrame (Dataset) Methods: DataFrame is just a Dataset of Row types, so you will look at the Dataset methods available at: http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.Dataset DataFrameStatFunctions: http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.DataFrameStatFunctions DataFrameNaFunctions http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.DataFrameNaFunctions Column methods: http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.Column Functions: http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.functions$ Dataset: http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.Dataset
Joins
Joins bring together a large number of different datasets. It helps avoid OutOfMemory issues and solve problems.
Join Expressions
- Join expressions determine whether two rows should join A join brings together two sets of data, the left and the right, by comparing the value of one or more keys of the left and right and evaluating the result of a join expression that determines whether Spark should bring together the left set of data with the right set of data.
Join types
The join type determines what should be in the result set.
Inner joins (keep rows with keys that exist in the left and right datasets)
Outer joins (keep rows with keys in either the left or right datasets)
Left outer joins (keep rows with keys in the left dataset)
Right outer joins (keep rows with keys in the right dataset)
Left semi joins (keep the rows in the left, and only the left, dataset where the key appears in the right dataset)
Left anti joins (keep the rows in the left, and only the left, dataset where they dos not appear in the right dataset)
Natural joins (perform a join by implicitly matching the columns between the two datasets with the same names)
Cross (or cartesian) joins (match every row in the left dataset with every row in the right dataset)
Create a simple dataset:
person = spark.createDataFrame([(0, "Bill Chambers", 0, [100]),(1, "Matei Zaharia", 1, [500, 250, 100]),(2, "Michael Armbrust", 1, [250, 100])])\.toDF("id", "name", "graduate_program", "spark_status")graduateProgram = spark.createDataFrame([(0, "Masters", "School of Information", "UC Berkeley"),(2, "Masters", "EECS", "UC Berkeley"),(1, "Ph.D.", "EECS", "UC Berkeley")])\.toDF("id", "degree", "department", "school")sparkStatus = spark.createDataFrame([(500, "Vice President"),(250, "PMC Member"),(100, "Contributor")])\.toDF("id", "status")
Register these tables:
person.createOrReplaceTempView("person")graduateProgram.createOrReplaceTempView("graduateProgram")sparkStatus.createOrReplaceTempView("sparkStatus")
Inner Joins
- Evaluate the keys in both of the DataFrames or tables and include only the rows that evaluate to true. Join graduateProgram DataFrame with the person DataFrame.
joinExpression = person["graduate_program"] == graduateProgram['id']#keys don't exist in both DataFrames so the following expression results in zero values.wrongJoinExpression = person["name"] == graduateProgram["school"]person.join(graduateProgram, joinExpression).show()
We can also specify this explicitly by passing in a third parameter, the joinType.
joinType = "inner"person.join(graduateProgram, joinExpression, joinType).show()
Outer Joins
- Evaluate the keys in both of the DataFrames or tables and includes (and joins together) the rows that evaluate to true or false. If there is no equivalent row in either the left or right DataFrame, Spark will insert null.
joinType = "outer"person.join(graduateProgram, joinExpression, joinType).show()
Left Outer Joins
- Left outer joins evaluate the keys in both of the DataFrames or tables and includes all rows from the left DataFrame as well as any rows in the right DataFrame that have a match in the left DataFrame. If there is no equivalent row in the right DataFrame, Spark will insert null.
joinType = "left_outer"graduateProgram.join(person, joinExpression, joinType).show()
Right Outer Joins
- Right outer joins evaluate the keys in both of the DataFrames or tables and includes all rows from the right DataFrame as well as any rows in the left DataFrame that have a match in the right DataFrame. If there is no equivalent row in the left DataFrame, Spark will insert null.
joinType = "right_outer"person.join(graduateProgram, joinExpression, joinType).show()
Left Semi Joins
- Semi joins do not actually include any values from the right DataFrame. They only compare values to see if the value exists in the second DataFrame. If the value does exist, those rows will be kept in the result, even if there are duplicate keys in the left DataFrame. Think of left semi joins as filters on a DataFrame, as opposed to the function of a conventional join.
joinType = "left_semi"graduateProgram.join(person, joinExpression, joinType).show()
Left Anti Joins
- Left anti joins are the opposite of left semi joins. Like left semi joins, they do not actually include any values from the right DataFrame. They only compare values to see if the value exists in the second DataFrame. However, rather than keeping the values that exist in the second DataFrame, they keep only the values that do not have a corresponding key in the second DataFrame. Like a NOT IN SQL style filter.
joinType = "left_anti"graduateProgram.join(person, joinExpression, joinType).show()
Cross (Cartesian) Joins
- Cross-joins are inner joins that do not specify a predicate. Cross joins will join every single row in the left DataFrame to ever single row in the right DataFrame. This will cause an absolute explosion in the number of rows contained in the resulting DataFrame. If you have 1,000 rows in each DataFrame, the cross join of these will result in 1,000,000 (1,000 x 1,000) rows. For this reason, you must very explicitly state that you want a cross-join by using the following special syntax:
joinType = "cross"graduateProgram.join(person, joinExpression, joinType).show()
Challenges When Using Joins
Joins on Complex Types
- Any expression is a valid join expression, assuming that it returns a Boolean.
Handling Duplicate Column Names In a DataFrame, each column has a unique ID within Spark’s SQL Engine, Catalyst. This unique ID is purely internal and not something that you can directly reference. This makes it quite difficult to refer to a specific column when you have a DataFrame with duplicate column names. This can occur in two distinct situations:
- The join expression that you specify does not remove one key from one of the input DataFrames and the keys have the same column name
- Two columns on which you are not performing the join on have the same name
Note: If you partition your data correctly prior to a join, you can end up with much more efficient execution because even if a shuffle is planned, if data from two different DataFrames is already located on the same machine, Spark can avoid the shuffle.
Data Sources
- JSON: JSON objects have structure, and JavaScript (on which JSON is based) has at least basic types. This makes it easier to work with
- Parquet: Parquet is an open source column-oriented data store that provides a variety of storage optimizations, especially for analytics workloads. It provides columnar compression, which saves storage space and allows for reading individual columns instead of entire files. It is the default file format. Writing data out to Parquet for long-term storage because reading from a parquet file will always be more efficient than JSON or CSV. Another advantage of Parquet is that it supports complex types.
- ORC: ORC is a self-describing, type-aware columnar file format designed for Hadoop workloads. It is optimized for large streaming reads, but with integrated support for finding required rows quickly. ORC has no options for reading in data because Spark understands the file format well.
- JDBC/ODBC Connections
- Plain Text Files Each line in the file becomes a record in the DataFrame.
- CSV: Commma-Separated Values. Each line represents a single record, and commas separate each field within a record.
Community-created Data Sources
- Cassandra
- HBase
- MongoDB
- AWS Redshift
- XML
The Structure of the Data Sources API
Reading data:
DataFrameReader.format(...).option("key", "value").schema(...).load()
#format is optional because Spark will use the parquet format by default
#.option allows you to set key value configurations to parameterize how you will read data
#schema is optional if the data source provides a schema or if intend to use schema inference.
The foundation for reading data in Spark is the DataFrameReader. We access this through the SparkSession via the read attribute: spark.read
After we have a DataFrame reader, we specify several values:
the format (1)
the schema (2)
the read mode (3)
a series of options (4)
Example:
spark.read.format("csv").option("mode", "FAILFAST").option("inferSchema", "true").option("path", "path/to/file(s)").schema(someSchema).load()
Read Mode Reading data from an external source naturally entails encountering malformed data, especially when working with only semi-structured data sources. Read modes specify what will happen when Spark does come across malformed records.
Basics of Writing Data
The foundation for writing data is quite similar to that of reading data. Instead of the DataFrameReader, we have the DataFrameWriter. Because we always need to write out some given data source, we access the DataFrameWriter on a per DataFrame basis via the write attribute: dataFrame.write
Specify three values: the format, a series of options, and the save mode. At a minimum, you must supply a path. Example:
dataframe.write.format("csv").option("mode", "OVERWRITE").option("dateFormat", "yyyy-MM-dd").option("path", "path/to/file(s)").save()
Save Mode
- Save modes specify what will happen if Spark finds data at the specified location. The default is errorIfExists. This means that if Spark finds data at the location to which you’re writing, it will fail the write immediately.
SparkSQL
With SparkSQL you can:
- Run SQL queries against views or tables organized into databases
- Use system functions of define user functions and analyze query plans in order to optimize their workloads
- You can choose to express some of your data manipulations in SQL and others in DataFrames and they will compile to the same underlying code
What is SQL?
- Structured Query Language
- Domain-specific language (A domain-specific language is created specifically to solve problems in a particular domain and is not intended to be able to solve problems outside it (although that may be technically possible).
- In contrast, general-purpose languages are created to solve problems in many domains.)
- For expressing relational operations over data, it is used in all relational databases.
Spark SQL
The power of Spark SQL derives from:
SQL analysts can take advantage of Spark’s computation abilities by plugging into the Thrift Server or Spark’s SQL interface
Data engineers and scientists can use Spark SQL where appropriate in any data flow.
- This unifying API allows for data to be extracted with SQL, manipulated as a DataFrame, passed into one of Spark MLlibs large scale machine learning algorithms, written out to another data source and everything in between.
Spark SQL is intended to operate as a online analytic processing (OLAP) database. This means that it is not intended to perform very extremely-low-latency queries.
| OLAP (Online Analytic Processing) | OLTP (Online Transaction Processing) |
|---|---|
| Deals with Historical Data or Archival Data. OLAP is characterized by relatively low volume of transactions. Queries are often very complex and involve aggregations. For OLAP systems a response time is an effectiveness measure. OLAP applications are widely used by Data Mining techniques. In OLAP database there is aggregated, historical data, stored in multi-dimensional schemas (usually star schema). Sometime query need to access large amount of data in Management records like what was the profit of your company in last year. | Is involved in the operation of a particular system. OLTP is characterized by a large number of short on-line transactions (INSERT, UPDATE, DELETE). The main emphasis for OLTP systems is put on very fast query processing, maintaining data integrity in multi-access environments and an effectiveness measured by number of transactions per second. In OLTP database there is detailed and current data, and schema used to store transactional databases is the entity model (usually 3NF). It involves Queries accessing individual record like Update your Email in Company database. |
Spark SQL CLI
- You can make Spark SQL queries in local mode from the command line. It cannot communicate with the Thrift JDBC server. To start Spark SQL CLI, run the following in the spark directory:
./bin/spark-sql - It is also possible to execute sql in an ad hoc manner via any of Spark's language by calling the method "sql" on the SparkSession object.
spark.sql("SELECT 1 + 1").show()
Note: You can completely interoperate between SQL and DataFrames e.g you can create a DataFrame, manipulate it with SQL, and then manipulate it again as a DataFrame.
Convert DataFrame to SQL:
spark.read.json("/data.json")\.createOrReplaceTempView("some_sql_view")
Catalog
The highest level abstraction in Spark SQL is the Catalog. The Catalog is an abstraction for the storage of metadata about the data stored in your tables as well as other helpful things like databases, tables, functions, and views. The catalog is available in the org.apache.spark.sql.catalog.Catalog package and contains a number of helpful functions for doing things like listing tables, databases, and functions. We will talk about all of these things shortly It’s very self explanatory to users, so we will omit the code samples here but it’s really just another programmatic interface to Spark SQL. This chapter shows only the SQL being executed; thus, keep in mind if you’re using the programmatic interface that you need to wrap everything in a spark.sql function call to execute the relevant code.
Tables
To do anything useful with Spark SQL you first need to define tables. Tables are a structure of data against which you run commands. We can join tables, filter them, aggregate them, and perform different manipulations. The core difference between tables and DataFrames is that you define DataFrames in a scope of a programming language, whereas you define tables within a database. This means that when you create a table (assuming you never changed the database), it will belong to the default database.
In Spark 2.X, tables always contain data. There is no notion of a temporary table: these are just views that do not contain data. This is important because if you go to drop a table, you can risk losing the data when doing so.
Spark-Managed Tables
- There are managed tables and unmanaged tables.
- When you define a table from files on disk, you are defining an unmanaged table.
- When you use saveAsTable on a DataFrame you are creating a managed table for which Spark will keep track of all the relevant information for you.
- This will read your table and write it out to a new location in Spark format.
- You can see this reflected in the new explain plan.
- In the explain plan you will also notice that this writes to the default Hive warehouse location. You can set this by setting the spark.sql.warehouse.dir configuration to the directory of your choosing when you create your SparkSession.
Tables store two important information:
- data within the tables
- data about the tables, that is, metadata
Views
Now that you created a table, another thing that you can define is a view. A view specifies a set of transformations on top of an existing table—basically just saved query plans, which can be convenient for organizing or reusing your query logic. Spark has several different notions of views. Views can be global, set to a database, or per session.
Creating Views
To an end user, views are displayed as tables, except rather than rewriting all of the data to a new location, they simply perform a transformation on the source data at query time. This might be a filter, select, or potentially an even larger GROUP BY or ROLLUP.
Views A view specifies a set of transformations on top of an existing table—basically just saved query plans, which can be convenient for organizing or reusing your query logic. Spark has several different notions of views. Views can be global, set to a database, or per session.
Creating Views To an end user, views are displayed as tables, except rather than rewriting all of the data to a new location, they simply perform a transformation on the source data at query time. This might be a filter, select, or potentially an even larger GROUP BY or ROLLUP.
Sourcers/Credits:
To be completed